阅读顺序
- 先会读:看懂字面量、字符类、量词和锚点,能解释一条正则为什么命中。
- 再会控边界:能用
^、$、\b、非贪婪和排除字符类缩小范围。 - 然后会取数据:用捕获组、命名组、全局匹配和替换模板把文本变成结构化字段。
- 最后进阶:理解 lookaround、回溯、跨语言差异和正则 DoS 风险。

如果你已经能熟练写基础正则,可以把这一节当速查表;如果读后面遇到卡点,先回到这里补齐“字符、位置、分组、重复、模式”这五件事。
^、$、\b、非贪婪和排除字符类缩小范围。.匹配任意单个字符;是否跨换行取决于 dotAll / singleline 模式。\d \w \s数字、单词字符、空白;Unicode 语义在不同语言中不完全一致。[abc] [^,]字符类与排除字符类;解析 CSV、日志字段时常比 .* 稳。* + ? {m,n}重复次数;先问“最多会多长”,再决定是否允许无限重复。^ $ \b位置断言,不消费字符;多行模式会改变 ^/$ 的含义。(...) (?:...)捕获组与非捕获组;只为分组不取值时优先用 (?:...)。|分支选择;多数回溯引擎按左到右尝试,不等同于“最长优先”。g i m s u常见 flags:全局、忽略大小写、多行、dotAll、Unicode。能写邮箱/日期/日志字段的正反样例;能说明每个分组取什么;能解释为什么某行不该匹配。
.* 太宽、未转义特殊字符、忘记多行模式、把全角/emoji/中文当 ASCII 处理。
遇到嵌套结构、完整 HTML/JSON、带状态的语法或安全敏感输入时,优先考虑 parser 或线性引擎。
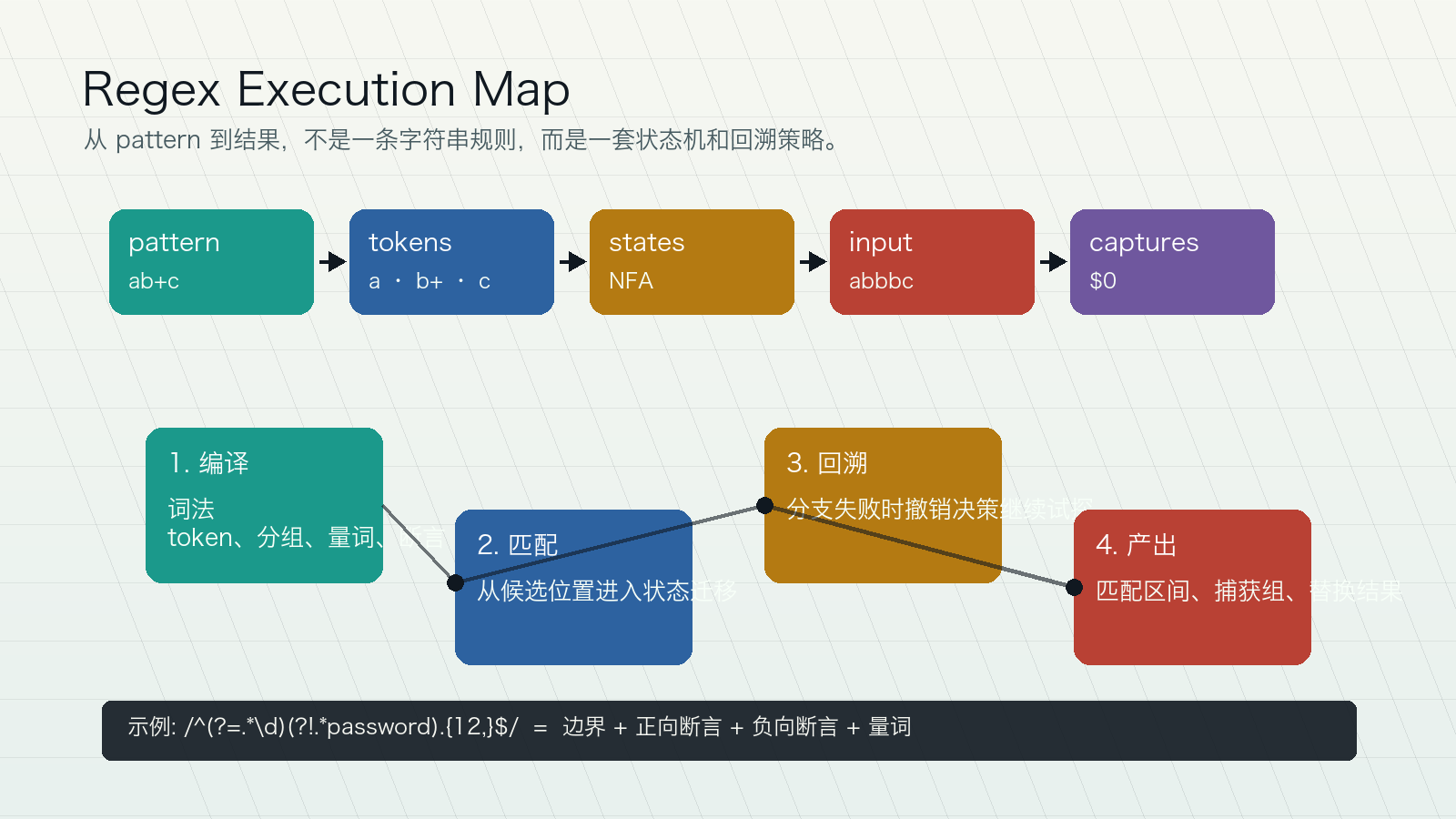
中高阶正则的关键不是语法密度,而是把“表达式、引擎、输入、约束、测试”连起来。你可以按顺序学习,也可以先跳到你正在踩坑的模块。
把 pattern 看成编译后的状态机,而不是一串魔法字符。
用锚点、词边界、lookaround 和捕获范围减少误匹配。
识别嵌套量词、歧义分支、贪婪匹配带来的回溯风险。
把规则沉淀为样例、测试、替换管道和跨语言兼容约束。
当你写下 /ab+c/,多数现代语言会先解析 token,再由引擎在输入串上尝试状态迁移。失败并不一定结束:回溯型引擎会撤销之前的选择,尝试另一个分支。
人写的规则,包含字面量、字符类、分组、量词、断言。
解析后的语法单元。真正的复杂度从这里开始。
回溯 NFA、DFA、POSIX、RE2 风格会有不同承诺。
候选起点、边界、Unicode 模式和换行策略影响结果。
匹配区间、捕获组、命名组、替换结果和失败原因。
JavaScript、Python、PCRE、Java 常见。功能强,支持复杂断言和捕获,但要自己管理性能风险。
Go 的 RE2、Rust regex 偏向线性时间,通常禁用回溯相关高级特性,例如 lookaround 和反向引用。
一些 Unix 工具或库强调最左最长匹配,和 PCRE/JS 的“第一个成功分支”直觉不同。
修改 pattern、flags 和输入文本,观察命中片段与简化 token 解析。这里使用浏览器 JavaScript 的 RegExp,所以语义接近现代 JS 引擎。
适合快速验证边界、捕获、量词和 Unicode flag 的影响。
^、$、\b、lookahead、lookbehind 都在问同一件事:当前位置的左边或右边是否满足条件。掌握断言后,正则会从“抓一段字符”升级为“在正确位置抓字符”。
X(?=Y) 匹配 X,但要求后面跟着 Y;X(?!Y) 匹配 X,但要求后面不是 Y。常用于密码规则、排除后缀、切割边界。
(?<=Y)X 匹配 X,但要求前面是 Y;(?<!Y)X 要求前面不是 Y。跨语言支持不稳定,迁移前必须验证。
切换任务,观察“匹配文本”和“约束位置”的差异。
回溯不是坏事,它让正则可以表达复杂结构。问题在于某些 pattern 会产生指数级候选路径,尤其是嵌套量词、重叠分支和失败结尾组合在一起时。
这是教学模拟,不会真的卡住浏览器;它估算候选路径增长,帮助你识别风险形态。
把 .* 换成更窄的字符类,例如 [^<]*、[^,]+、[A-Z0-9_]+。
使用有界量词 {0,64},对用户输入尤其重要。无限重复要有明确边界。
高风险在线输入可选 RE2/Rust regex;复杂语法要用 parser,不要把正则当语法树生成器。
中高阶用法里,正则通常不只是判断 true/false,而是把文本结构化:命名组、替换模板、回调替换、逐行抽取,都是把文本处理管道工程化的关键。
使用 JavaScript 替换语义,支持 $1、$<name> 等常见模板。
日志、配置、半结构化文本适合正则;嵌套语言、HTML、JSON 语法树不适合只靠正则。下面的实验展示如何把命名捕获转成结构化记录。
选择规则后会显示解析表和未匹配行,帮助你把正则纳入数据质量检查。
| # | fields |
|---|
先写“不应该匹配”的样例:空值、转义符、跨行、超长输入、相邻分隔符。
复杂抽取可以分阶段:粗切行、字段校验、再做业务解析。可读性通常比单条巨型正则更值钱。
在代码注释或测试名里写明目标引擎:JS、Python、PCRE、RE2。否则迁移时很容易误判。
外部输入必须设置长度、超时或线性引擎。正则 DoS 是工程问题,不是语法问题。
跨语言迁移时,最危险的是默认以为语法和性能语义一致。下面的矩阵可以作为代码评审和迁移清单。
| 能力 | JavaScript | Python re | PCRE2 | Go / RE2 | Rust regex | 工程建议 |
|---|---|---|---|---|---|---|
| 命名组 | (?<name>...) | (?P<name>...) | 多语法 | (?P<name>...) | (?P<name>...) | 不要直接复制替换模板。 |
| Lookbehind | 现代引擎支持,限制较多 | 固定宽度为主 | 能力强 | 不支持 | 不支持 | 需要可移植时改为两阶段匹配。 |
| 反向引用 | 支持 | 支持 | 支持 | 不支持 | 不支持 | 线性引擎通常牺牲这类能力。 |
| 原子组 / 占有量词 | 通常不支持 | 新版本支持原子组 | 支持 | 不支持 | 不支持 | 先用结构改写,别依赖特性救火。 |
| Unicode 属性 | /\p{Letter}/u | 标准 re 较弱 | 强 | 部分支持 | 支持 | 涉及中文、emoji、组合字符时必须实测。 |
| 超时/线性保证 | 无内置统一超时 | 标准库无超时 | 可配置 match limit | 线性时间 | 线性时间 | 用户输入优先 RE2/Rust 或外层限时。 |
生产环境里的正则应当有输入边界、测试样例、失败模式和变更记录。可读性不足时,拆成命名步骤通常比压成一行更可靠。
文本来源、最大长度、换行模式、编码、是否允许嵌套、是否需要全局匹配。
至少包含 3 个命中样例、3 个不命中样例、1 个边界样例、1 个恶意长输入。
在测试里使用真实目标语言的引擎,而不是在线 regex 网站的默认 PCRE。
命名组优先。注释里说明每个组的业务含义,替换模板里避免神秘的 $7。
对外部输入设置长度上限或超时;高流量路径做基准测试,警惕嵌套量词。
当需求变成完整语法解析、嵌套结构或多状态协议时,把正则替换为 parser。
答案会即时显示。这里重点考工程判断,而不是死记语法。
还没有答题。
建议先补引擎模型,再读各语言文档。不要只收藏 cheatsheet,它解决不了回溯和可维护性问题。
先看目标语言的正则文档,再读 Friedl 的 Mastering Regular Expressions,最后按需学习 RE2、PCRE2、Rust regex 的设计取舍。
把工作中 5 条复杂正则收集起来,为每条补正反样例、性能样例、语义注释和迁移说明。这比刷 100 个孤立题更有效。